One of the most frequent format for data import and export in python is CSV. Reading and loading a CSV file to pandas is straightforward – assuming you know the separator, or the separator is a comma. While the name Comma Separated Values implies CSV file automatically use comma as separator (also called delimiter) this is not always the case. Depending on your settings the separator can be anything from semicolons to pipe character. Fortunately, there is a way to automate delimiter identification and to make reading CSV files smooth.
When you use your code, the issue does not make a problem. You check your settings and define your delimiter accordingly. But when you build any application for wider use you need to make sure that reading the file will not run into an error because of the incorrect parameter in the function call.
Imagine you create a solution used by other users. These users need to update a CSV file on a regular basis to run your application, and you have no control of their system setting. How do you make sure that reading the regular CSV file will work whoever updates the file? I just ran into this issue as I am building an algorithm which will be used by one of the departments of the company I am working for. I will baby sit the algo use for a while but afterwards the solution must run without manual intervention.
One of the inputs we use is a table of holidays and special workdays. We need identify the current day of the week but if the current day happen to be a holiday than the day’s expected pattern wil be different from what the weekday() attribute would imply. We also have special Saturdays which are workday to make up for lost days on long weekends. (When, for instance, a holiday falls on Tuesday, the preceding Monday is also a non-working weekday, for which the country makes up on a Saturday. While it is a handy solution to make long weekends with the family it makes the work of a data scientist a bit more tedious.) Beyond holidays and Saturday workdays we also identified that weekdays between Christmas and New Years Day can also be unlike ‘ordinary’ workdays.
Let’s imagine this CSV file which lists public holidays, special Saturday workdays and Christmas period weekdays. We code these days with numbers 7, 8 and 9, to augment the [0-6] values given by the weekday() function. The software in which the CSV file is written uses semicolon as delimiter. If we import the data to pandas we get this.
import pandas as pd
import csv
csvfile = '..\\holidays.csv'
df = pd.read_csv(csvfile, index_col = 0)
df.iloc[0:5,:]
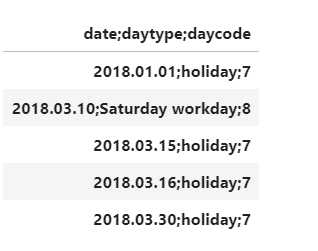
As you see the pd.read_csv() function incorrectly identified each row as a single column and put it in the index series, as told by the ‘index_col = 0’ parameter. How can we automate delimiter recognition to avoid this mess? The solution comes with the csv package. We need to read one line of the csv file and identify the file’s ‘*dialect*’ and get the delimiter attribute. If we feed this attribute into the pd.read_csv() call our dataframe comes out nice and pretty.
f = open(csvfile)
sniffer = csv.Sniffer()
dialect = sniffer.sniff(f.readline())
delim = dialect.delimiter
f.close()
df = pd.read_csv(csvfile, sep = delim, index_col=0)
df.iloc[0:5,:]
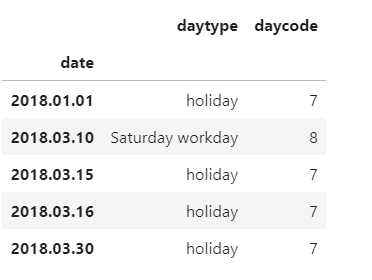
As I said this is a real issue I needed to handle, and this is the CSV file we are using in production. It has to be updated once a year around December when the next year’s holiday schedule, with special regards to Saturday workdays, goes public. Whoever updates the holiday info it will be smoothly read into the application.
Codes are at the usual place.